IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包,是一个基于Maven构建的项目具有60万字/秒的高速处理能力支持用户词典扩展定义。
IK支持Analyzer: ik_smart , ik_max_word , Tokenizer: ik_smart , ik_max_word
ik_max_word: 会将文本做最细粒度的拆分,比如会将”中华人民共和国国歌”拆分为”中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将”中华人民共和国国歌”拆分为”中华人民共和国,国歌”。
IK分词有自己的词库,包含关键词词库和停用词词库,同时也支持扩展自定义词库,其中关键词词库会把搜索语句按照关键词切割,停用词词库会直接去掉不参与分词。
1.在线安装
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
速度较慢,不推荐
2.离线安装
2.1查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
显示结果:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中。
2.2解压缩分词器安装包
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
2.3 上传到es容器的插件数据卷中
2.4 重启容器
docker restart es
2.5 查看es日志
docker logs -f es
3.测试:
IK分词器包含两种模式:
ik_smart:最少切分ik_max_word:最细切分
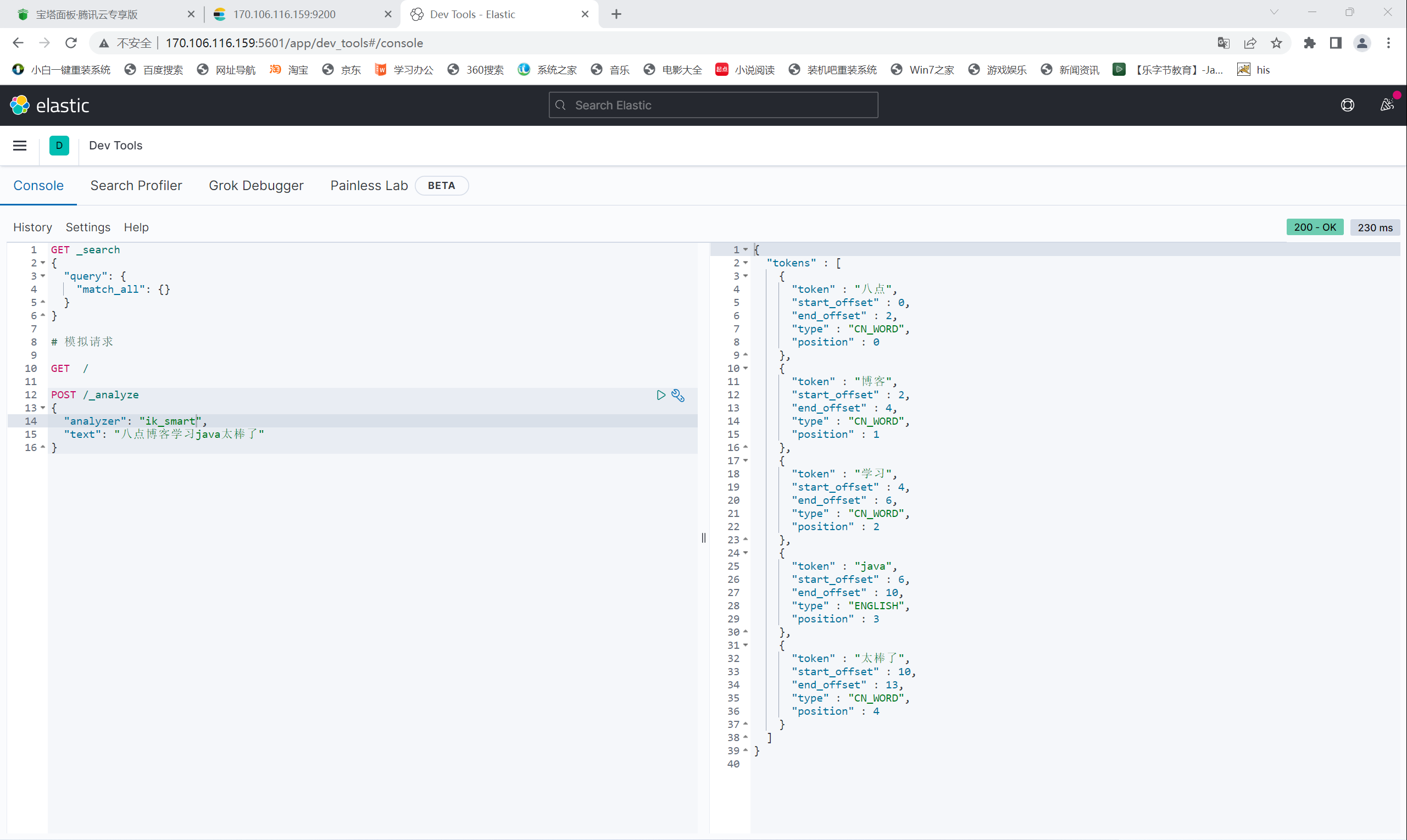
使用 ik_smart
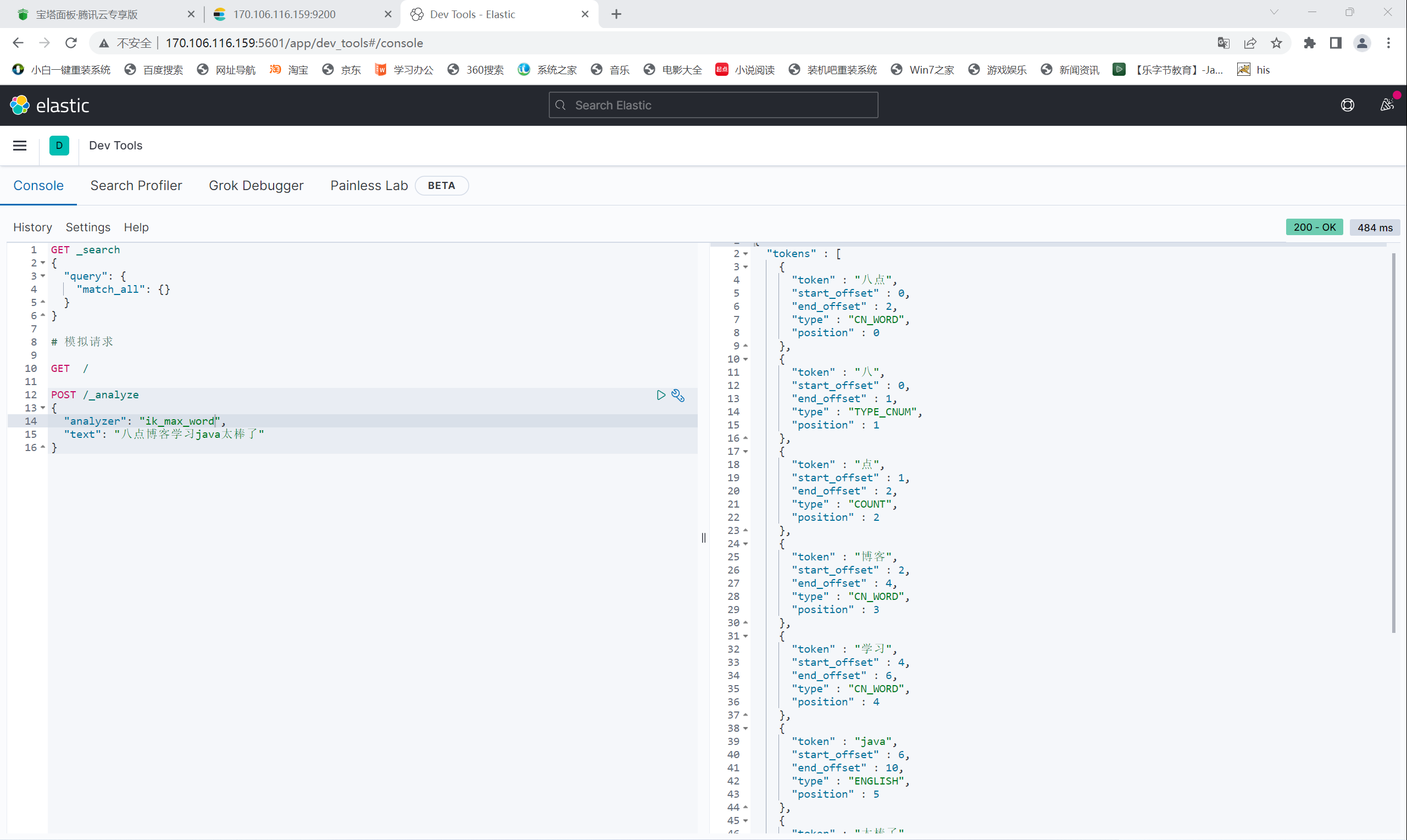
使用 ik_max_word